Everyone's obsessed with bigger AI models, but here's the thing - small language models (SLMs) are quietly doing the heavy lifting in ways that might surprise you.
The Smart Pipeline Approach
Instead of sending every single query to a massive 70B parameter model (expensive and slow), what if you used a smaller 3B model as your first line of defense?
Think of it like this: the small model handles the easy stuff, filters out noise, and only escalates the tricky questions to the big model. It's like having a really good assistant who knows when to bother the CEO and when to handle things themselves.
This isn't just theory - companies are seeing 80% cost reductions while maintaining quality where it actually matters.
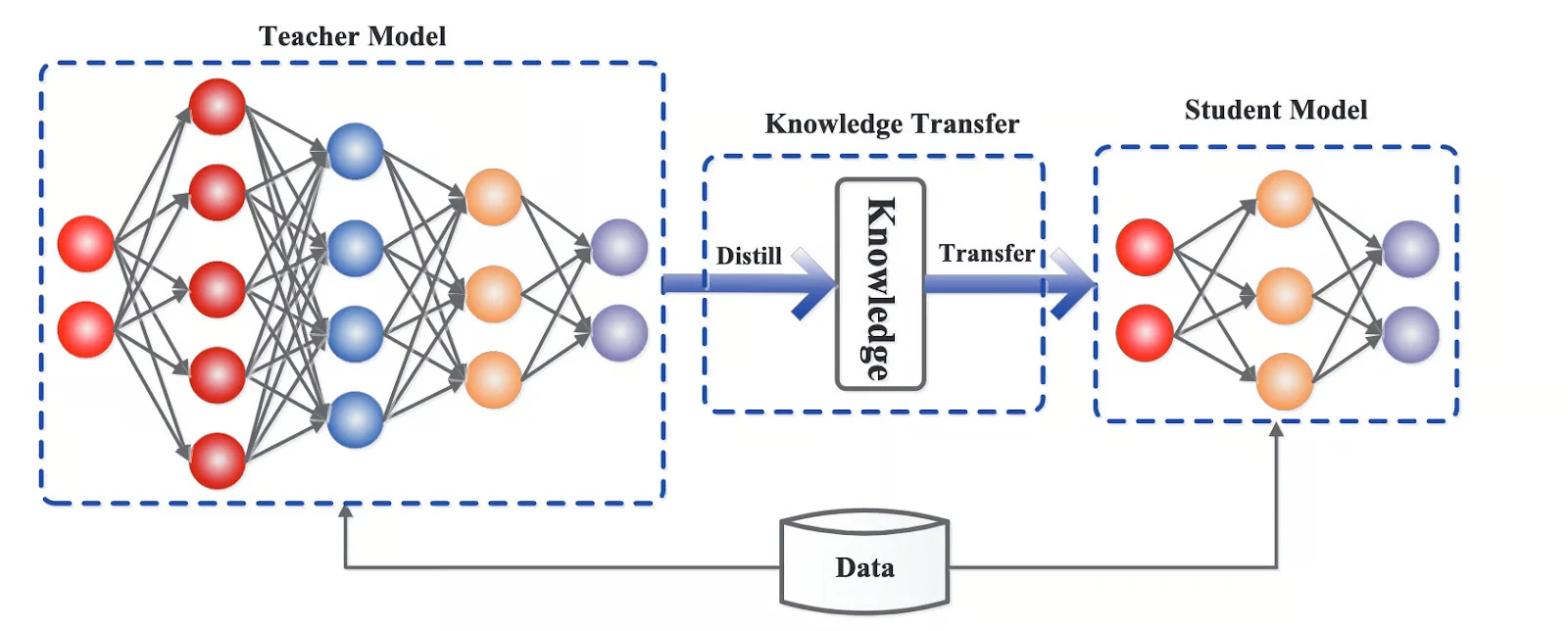
What's Distillation All About?
Here's where it gets interesting. Distillation is basically having a master model teach a smaller student model. The big model doesn't just share answers - it teaches the smaller one how to think.
The result? A 6B parameter model that can handle tasks almost as well as its 70B teacher, but runs 10x faster and costs a fraction to operate.
Why This Actually Matters
Let me give you some real examples where this is already working:
Mobile Apps: Instead of sending every chat message to the cloud, a small model runs locally and handles 80% of queries. Only the complex stuff gets escalated. Users get instant responses most of the time.
Content Moderation: A small model quickly catches obvious spam or inappropriate content. The edge cases (like detecting subtle sarcasm) get passed to the big model.
Code Completion: Your IDE doesn't need a massive model to suggest simple completions. Save the heavy lifting for complex refactoring.
The Beauty of the Hybrid Approach
Here's the really clever part - you can chain these models together:
User Query → SLM (cleanup) → LLM (if needed) → SLM (polish)

The small model cleans up the input, the big model handles the heavy reasoning, and the small model polishes the output. Everyone does what they're best at.
Where This Shines
SLMs are perfect when you have constraints:
- Mobile apps with limited battery and memory
- Real-time systems that need sub-second responses
- Edge devices with no internet connection
- Budget-conscious applications where every API call counts
The Takeaway
The future isn't about building bigger and bigger models. It's about building smarter systems that know when to use the right tool for the job.
SLMs aren't just "diet LLMs" - they're specialized tools that make AI actually practical for real-world applications. And when you combine them with distillation, you get the best of both worlds: the intelligence of large models with the efficiency of small ones.
Sometimes the smartest solution isn't the biggest one.